

Barbero e i programmi di fact-checking
Che cosa verifichiamo? Come e perché?
La questione delle intelligenze generative non si può ridurre a un solo punto di vista.

Il 28 aprile 2023 ChatGPT ha riaperto in Italia – per tutti coloro che non hanno continuato a usarlo attraverso una VPN –, rispondendo ad alcune richieste del Garante della Privacy.
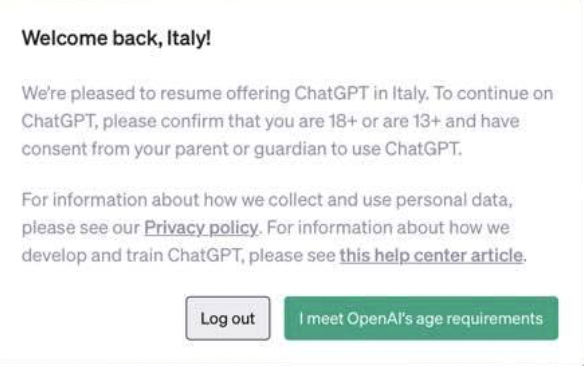
Funziona così. Quando si entra dentro al servizio, c’è un’avvertenza che dà il bentornato all’Italia e che chiede di confermare che si hanno 18 anni oppure almeno 13 ma con il consenso dei genitori. Si clicca e si può ricominciare a usare il servizio.
La maschera che appare a chi si ricollega dall’Italia – nota: si trova online, a me non è apparsa – si presenta così.
Si può cliccare su un pulsante verde confermando di rispondere ai requisiti richiesti, oppure fare il logout.
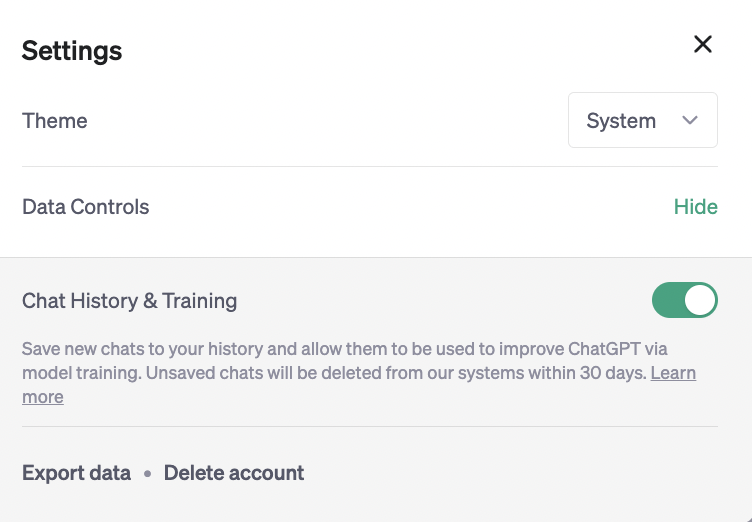
Decisamente più interessante la funzione che permette un minimo di controllo sui propri dati. Nella sezione delle impostazioni (qui le istruzioni dettagliate di OpenAI) c’è una sezione “Chat history & training“.
Disattivandola, “spegnendo” l’interruttore, secondo quando spiega OpenAI, le conversazioni verranno cancellate dopo 30 giorni e non verranno utilizzate per addestrare ulteriormente la macchina.
Se si vuole mantenere lo storico delle proprie conversazioni senza che queste vengano usate per addestrare il modello, allora c’è un form da compilare: in questo modo, si può continuare a lavorare mantenendo le proprie conversazioni pregresse, che possono essere la base per lavori strutturati e reiterati.
È molto utile e importante anche il fatto che OpenAI abbia reso possibile l’esportazione dei dati. Ne ho effettuata una per capire come funziona. Dopo un po’, arriva una mail che contiene una serie di file, un .hmtl e quattro file .json. I file .json si possono aprire anche con semplici editor di testo, come Notepad o Textedit.
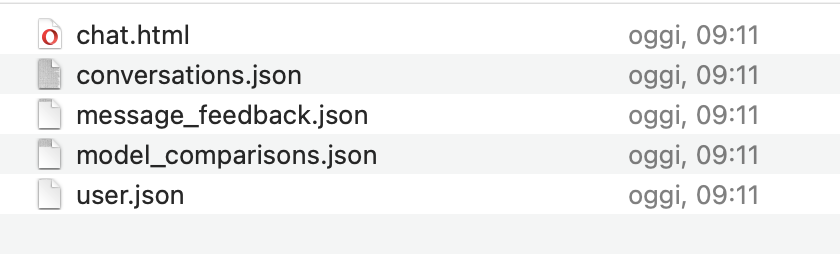
Quel che si ottiene con questa esportazione è:
C’è un modulo per fare Opt-in. Cioè, per autorizzare esplicitamente ChatGPT a utilizzare le proprie conversazioni per addestrare lo strumento.
C’è anche un modulo per chiedere cancellazioni o correzioni, nel caso in cui si ritenga che ChatGPT si basi su dati errati.
Il Garante della Privacy ha rilasciato un proprio comunicato soddisfatto, che poi però rimanda alla futura task force europea. Perché non c’è alcuna traccia della possibilità di rimuovere dati dal “set” di addestramento
Chiaramente, il giudizio che si può dare alla vicenda varia a seconda delle proprie inclinazioni personali e delle proprie idee.
L’idea che si possa risolvere una questione importante come quella delle nuove tecnologie basate su intelligenze artificiali con un pulsante e un po’ di burocrazia lascia il tempo che trova e rischia di trasformarsi in una foglia di fico.
C’è un problema enorme a monte, ed è il fatto che queste macchine non si possono ispezionare, sono opache.
Per capirci, anche in presenza delle novità introdotte da ChatGPT il 28 aprile 2023:
C’è chi pensa che questo sia l’inizio di una regolamentazione delle intelligenze artificiali; c’è chi festeggia la vittoria del Garante; c’è chi gioisce perché ritiene che questi elementi siano parzialmente a tutela del copyright e dunque della proprietà intellettuale.
Qui preferiamo un approccio decisamente più open access.
L’accesso libero alla cultura, alla conoscenza, alla produzione artistica e culturale non è nemico del giusto compenso a chi scrive, compone, dipinge, fotografa, crea (ci sarebbero poi altre soluzioni politiche, molto più interessanti, come il reddito di base universale, per esempio). L’accesso libero alla cultura è amico dell’umanità tutta.
È vero che queste macchine possono rendere i ricchi ancora più ricchi. Ma allo stesso tempo possono liberarci da molti lavori automatizzabili. Le posizioni del tipo «dobbiamo difenderci dalle macchine» rischiano di farci perdere di vista il fatto che la tecnologia può essere nostra alleata e rischiano anche di farci perdere di vista che il problema più grosso da risolvere è l’oligopolio di queste tecnologie.

Il 31 marzo 2023 il Garante della Privacy ha pubblicato un provvedimento nei confronti di OpenAI, la società che ha sviluppato il software ChatGPT. Ti consiglio di leggere integralmente il provvedimento. Lo trovi qui.
Parallelamente, il Garante della Privacy ha pubblicato anche un comunicato stampa che si intitola «Intelligenza artificiale: il Garante blocca ChatGPT. Raccolta illecita di dati personali. Assenza di sistemi per la verifica dell’età dei minori». Lo trovi qui.
Immediatamente si è scatenata una sovrapproduzione di contenuti, podcast, live che spiegano bene le cose, pareri, post, opinioni, dichiarazioni, tifo: una quantità soverchiante di contenuti nei quali sicuramente anche tu e io abbiamo trovato qualcosa che ci ha fatto sentire a nostro agio.
Qualcosa che ci ha fatto annuire e pensare: sì, è proprio così.
I filoni si sono divisi, più o meno, così: c’è chi ha iper-semplificato e ha detto, in vari modi, che il Garante ha bannato le intelligenze artificiali dall’Italia, stracciandosi le vesti per lo stato di degrado del Paese. C’è chi ha esultato per lo stop, inneggiando al lavoro del Garante che ha fermato quella fabbrica di fake news che è ChatGPT.
La cosa bella è che questi due atteggiamenti estremi – con in mezzo tutto ciò che si può immaginare in termini di polarizzazione ma anche, fortunatamente, di problematizzazione – si trova anche all’interno di mondi in cui ci sono persone esperte di un determinato settore.
In 48 ore, più o meno, sul tema è già stato detto tutto e il contrario di tutto, esaurendo il filone in attesa della prossima news. E allora, perché scriverne ancora? Perché è importante unire i puntini per la prossima volta: è una delle ossessioni di Slow News.
Uno dei temi da cui partire è: il Garante ha davvero bloccato ChatGPT? La risposta corretta è: sì e nì. Perché?
Il blocco si aggira agevolmente. Se hai una VPN, cioè se sai simulare una connessione da un altro paese, puoi tranquillamente continuare a usare ChatGPT. A proposito, non usarne a caso, per favore. Scegli bene. Un consiglio? ProtonVPN, anche nella versione free. E comunque, tieni d’occhio le news che la riguardano per capire se si mantiene sicura come è stata fino a oggi. Non ricevo alcuna percentuale per questo consiglio.
Anche se nel comunicato il Garante scrive testualmente di aver bloccato ChatGPT, nel provvedimento ha chiesto la «limitazione provvisoria del trattamento dei dati personali degli interessati stabiliti nel territorio italiano». Poi OpenAI ha annunciato di aver disabilitato l’accesso al software dall’Italia. Questo è bastato a sollevare una questione di lana caprina del tipo «ehi, vedi, se hanno chiuso non erano a norma», oppure «non è il Garante ad aver bloccato, sono loro che hanno chiuso». Però, è davvero impossibile immaginare il funzionamento di quello strumento senza poter trattare i dati delle persone sul territorio italiano. E quindi, in effetti, sì, chiedere la limitazione provvisoria del trattamento dei dati personali equivale, in pratica, a chiedere la sospensione del servizio.
In linea del tutto teorica, qualcosa di diverso si poteva fare nel caso in cui si potesse imporre al software ChatGPT di non usare nessuna delle informazioni italiane usate per l’addestramento della macchina, anche se rimarrebbero le questioni legate all’accesso dall’Italia, che comportano per forza di cose un trattamento di dati.
Quindi, per quanto io sia un amante di questioni di lana caprina, spero di averti tolto il dubbio. Su questo punto.
Va detto che il 20 marzo ChatGPT ha subito un data breach, ovvero una diffusione di dati dovuta a un bug. Cos’è successo esattamente? Stando a quanto riportato da svariate persone – l’1,2% delle persone paganti, secondo OpenAI, che ha confermato il problema –, chi si loggava dentro ChatGPT ha visto in alcuni casi esposti dati di altri. In particolare: nome, cognome, mail, titoli delle chat e in alcuni casi pare il primo messaggio della chat, le ultime quattro cifre della carta di credito e la data di scadenza della medesima. Non bello, per niente, ed è normale che si indaghi su questo.
Tuttavia, nel provvedimento del Garante si legge un’altra cosa fra le premesse che hanno portato alla decisione. Questo, in particolare: «RILEVATO che il trattamento di dati personali degli interessati risulta inesatto in quanto le informazioni fornite da ChatGPT non sempre corrispondono al dato reale».
Cosa significa? Che fra i dati trattati si includono, nel provvedimento, anche i dati che sono stati utilizzati per addestrare la macchina e i dati che la macchina fornisce in risposta a un comando.
Adesso, purtroppo, serve un minimo di spiegazione.
I Large Language Model testuali funzionano così (semplifico tantissimo per capirci). Tu dai loro un sacco di testo per “addestrarli”, loro lo usano per “imparare”.
Poi, in presenza di un comando testuale, sono in grado di generare altro testo (lo fanno prevedendo, cioè calcolando la probabilità che a una parola ne segua un’altra, sempre semplificando moltissimo, ai limiti dell’imprecisione, purtroppo).
Queste macchine soffrono di allucinazioni. Vuol dire che possono sbagliare, anche in presenza di dati corretti. Qui e qui puoi vedere alcune allucinazioni che mi riguardano.
Te lo ricordano in tutte le salse, su ChatGPT, su Bing, su Bard: questi strumenti possono sbagliare. Quindi non vanno usate come oracoli. E le persone che le usano andrebbero informate rispetto ai rischi, per un uso consapevole.
Se stiamo parlando di questi dati e di questo trattamento, allora quello che si mette in dubbio è l’intero impianto di funzionamento dei LLM e non solo.
E in effetti c’è chi dice che nessuno aveva il diritto, per esempio, di addestrare macchine di intelligenza artificiale generativa con testi pagine web, anche se consultabili liberamente, perché quelle pagine non erano lì per quello. So già che parlare di questo tema apre questioni ideologiche e quindi si rischia di passare rapidamente al tifo. Ripeto, però, un dato fondamentale: se mettiamo in discussione questo, si mette in discussione qualsiasi cosa che riguardi l’addestramento di reti neurali e, più in generale della cosiddetta intelligenza artificiale, e la domanda diventerebbe:
È consentito addestrare una macchina con dati presenti naturalmente nel mondo?
Tu hai una risposta a questa domanda? Io no. Ma ti faccio notare due cose. Uno: se non stessimo parlando di macchine, non ci porremmo nemmeno il problema. Nessuno si permetterebbe di dire che una studentessa non si può addestrare leggendo Wikipedia. E nessuno le direbbe di aver violato il GDPR se offre risposte sbagliate.
Due: non è “benaltrismo” ricordarci che addestriamo già, da decenni, macchine con i dati presenti naturalmente nel mondo, e meno male che l’abbiamo fatto, così almeno possiamo avere rapporti come quello dell’IPCC. Che poi la politica non ascolta, ma pazienza.
Uso il termine fake news anche se è improprio (vedi qui) e ti rispondo così: sì, certo.
C’è forse qualche macchina che può essere usata per produrre contenuti che non venga usata anche per generare fake news?
Nei prossimi giorni esce per TheFix una mia guida in cui ripercorro anche la storia delle macchine che sono state utilizzate, dal 1800 in poi, per manipolare fotografie e video.
Il provvedimento del Garante cita esplicitamente alcuni articoli del GDPR che verrebbero violati da OpenAI.
Non si rilevano sufficienti procedure per verificare che il servizio non sia utilizzato da persone sotto i 13 anni; si ritiene che l’informativa privacy non sia rispettosa del GPDR.
Su questi punti, molto specifici, l’istruttoria del Garante è pienamente nel merito dei suoi poteri e prerogative, quindi non si può proprio dire nulla, se non che aspettiamo l’esito dell’investigazione e del rapporto con OpenAI, che dovrebbe essersi aperto in funzione del provvedimento.
Non mi avrai.
Roberta Covelli e Giorgio Taverniti (fra tanti) dicono di sì, Luciano Floridi e Walter Quattrociocchi (fra tanti) dicono di no. E sono sicuro che troverai molto convincenti tutte le loro considerazioni, a seconda del tuo punto di vista. Ho scelto loro perché si sono distinti, a mio modo di vedere, nell’offrire argomentazioni ragionate e convincenti mentre altrove c’era chi (puoi verificare tu stessə) scriveva su giornali mainstream frasi tipo l’«Italia ha vietato le A.I.».
Non voglio cercare equidistanza tra le parti, non ce l’ho: sono assolutamente convinto che la situazione andasse gestita diversamente.
Ma aggiungerò una serie di ragionamenti:
– proteggere i dati delle persone è doveroso, e non importa se altri non li proteggono
– tocca mettersi d’accordo su quali dati, naturalmente
– per mettersi d’accordo su quali dati, bisogna studiare bene il funzionamento di una tecnologia, capirla, smontarla
– questo significa che le tecnologie devono essere trasparenti e smontabili
– non è detto che dobbiamo per forza accettare senza ribattere un’innovazione tecnologica: questa è una visione deterministica e fideistica. Le moratorie esistono (per dire, io sono uno di quelli che gradirebbe fortemente una moratoria internazionale delle tecnologie di riconoscimento facciale per motivi legati al controllo delle identità delle persone, anche se so bene quanto sarebbe complicato farlo una volta che queste tecnologie sono state diffuse) e si possono benissimo prendere in considerazione
– allo stesso tempo, non possiamo rifiutare il fatto che le tecnologie esistano e che possano avere contemporaneamente degli elementi positivi (i LLM ne hanno tantissimi) e degli elementi negativi (idem)
– vietare e proibire alle persone comuni – perché poi è di questo che stiamo parlando, mi pare ovvio: il problema è nato perché queste tecnologie sono diventate pop, di massa – non mi sembra rappresentare una soluzione, piuttosto è meglio smontare, rimontare, insegnare, capire collettivamente come fare
– il problema dei LLM e di quello che rappresentano e rappresenteranno – così come i problemi di qualsiasi tecnologia – non può essere affrontato da un solo punto di vista. Non può essere solo appannaggio degli ingegneri né dei soli filosofi, non è solo un problema economico né soltanto etico, non è un problema solamente sociologico e nemmeno un problema solamente antropologico, non è soltanto un problema di privacy né soltanto un problema legale
– eppure la questione è, contemporaneamente, tutte queste cose insieme, ed è anche un problema politico (per dire, una mia speranza – che so già mal riposta, ma sperare non costa nulla – è che queste macchine diventino un acceleratore per il reddito di base universale). Questo significa che va affrontato in maniera olistica
– ci sarebbe tanto bisogno di pensare a governance globali tenendo presente le differenze locali: è, probabilmente, la sfida più grossa dell’umanità, come ci sta dimostrando quella spada di Damocle della crisi climatica
– ci sarebbe tanto bisogno di pensare a come far diventare la tecnologia uno strumento abilitante e non un motore riproduttivo di disuguaglianze.
Insomma, se vuoi proprio una risposta definitiva, è questa: la risposta troviamola insieme.
Detto questo, credo di dover elencare gli effetti negativi indesiderabili della decisione del Garante:
– la conversazione si è polarizzata ancor di più
– molte persone si avvicineranno alle VPN senza competenze specifiche, col rischio di affidarsi a servizi non affidabili
– molte persone si avvicineranno a vere o presunte “alternative” a ChatGPT potenzialmente ancor più “rischiose” dal punto di vista della privacy e sicuramente non monitorate con attenzione, né dalla stampa né dal Garante stesso
– il divario tra chi sa di tecnologia e chi non ne sa aumenta ancora, anziché diminuire.
Ci sono anche effetti collaterali positivi, ovviamente:
– ne stiamo parlando
– ci stiamo ponendo problemi complessi e importanti. Per esempio?
Ho il diritto di far dimenticare qualcosa di mio a queste macchine?
Come correggo i dati errati su di me?
Ci sono cose di queste tecnologie dalle quali devo proteggermi?
Ho il diritto di scegliere se un mio lavoro non vada usato per addestrare queste macchine?
Come cambia e cambieremo il diritto d’autore?
Come cambia e cambieremo l’apprendimento?
Come regolamenteremo queste tecnologie e come miglioreranno davvero le nostre vite?
In generale, che mondo immaginiamo?
Quel che dovremmo auspicare, al di là del tifo, è che le aziende che sviluppano tecnologie siano attente alla sicurezza dei loro strumenti, a partire dall’uso che se ne può fare. Che ci sia maggiore consapevolezza tra le persone (siamo una nicchia, qui. Moltissime persone, la fuori, non sanno nemmeno di cosa stiamo parlando), che si sviluppi una conversazione ampia e internazionale su questi temi.
Fuori dalla collettività c’è solo la mitomania (cit.)
L’immagine che illustra questo contenuto è stata creata con un’Intelligenza Artificiale generativa.
Che cosa verifichiamo? Come e perché?

Sì, ed è il motivo principale per cui è schierato quasi sempre dal punto di vista di chi ha di più, mentre tutti gli altri — che sono molti di più — restano sistematicamente esclusi.

E se le vediamo così, cambia davvero tutto

Ogni giornale è un’operazione politica, anche Slow News. Ma Slow News non viene da nessun partito e non nasconde da che parte si schiera: quella di chi non ha voce